Chaos
We have a situation here where we would like to allow those with the necessary skills, but who may not be full-blown developers, to experiment with and make changes to our (PostgreSQL) database.
In the past, this has been done by having a shared "development" DB, with any changes made there manually "migrated" to the production DB in a very ad-hoc manner.
This is problematic for a few reasons, but mainly because changes to the production server are unmanaged, and hence, its current state is fairly chaotic.
Control
Ideally, we want people to have the ability to do their (development) work using the tools that they are already familiar with, but at the same time, provide an easy and well managed path to get their changes from development to production.
Controlled Chaos
I am going to propose a workflow which I believe can give us control while still maintaining a (good) level of chaos!
You will need:
- a unixy OS, e.g. linux or OS X
- virtualbox
- vagrant
- vagrant-berkshelf plugin
- git
So let's clone the associated github project and fire up vagrant:
$ git clone https://github.com/jkburges/emii_toolkit.git
$ cd emii_toolkit/
$ vagrant up
Bringing machine 'default' up with 'virtualbox' provider...
[default] Importing base box 'ubuntu-12.04-omnibus-chef'...
.
<snip>
.
[2013-09-18T05:48:26+00:00] INFO: Chef Run complete in 454.580271656 seconds
[2013-09-18T05:48:26+00:00] INFO: Running report handlers
[2013-09-18T05:48:26+00:00] INFO: Report handlers complete
$
Success (I hope)!
The code (and the VM) is all there for you to take a look at if you're interested, so I am not going to go in to how this all works. Instead, let's go straight to an…
Example Workflow
Let's say one of my colleagues would like to add a new table to the database, using his or her tool of choice, pgAdmin. Here's how to do it:
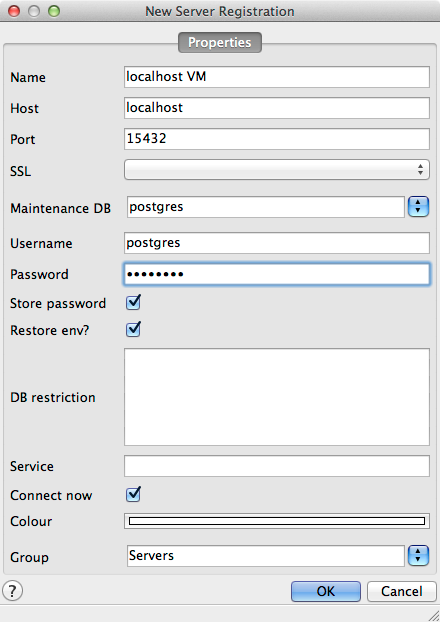
- Create a connection to the database residing within the VM (noting that the port is 15432 and password is postgres):
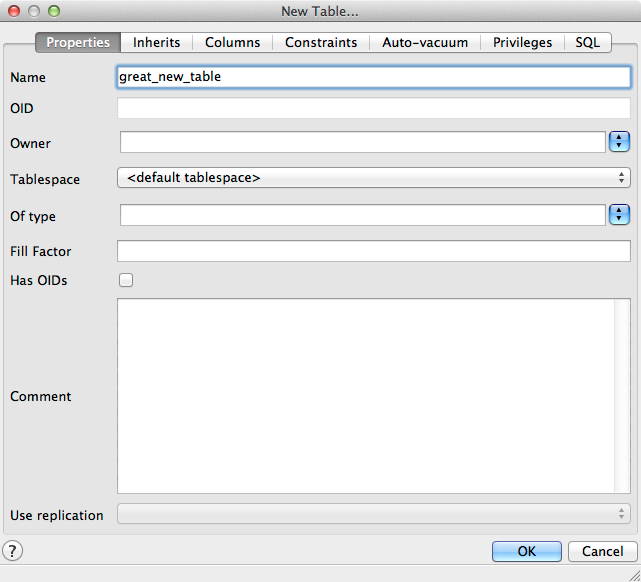
Create the new table under localhost VM/geoserver/public/tables:
Run the diff script:
$ bin/diffChangeLog.sh great_new_table
The way I've set this up is to have a different git project for the DB migrations (to keep them separate from all the vagrant/environment infrastructure). However, it lives within our current hierarchy, and we can go there to see what changes have been made to that repo:
$ cd workspace/emii_db/
$ git status
#
# modified: changelog.xml
#
# Untracked files:
#
# great_new_table.changelog.xml
Examining the contents of great_new_table.changelog.xml, we see that our changes made in PgAdmin have been turned in to "code":
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-2.0.xsd">
<changeSet author="vagrant (generated)" id="1379502017306-1">
<createTable tableName="great_new_table">
<column name="id" type="int8"/>
</createTable>
</changeSet>
</databaseChangeLog>
The great thing about this is that it allows us to now manage this like any other source code: version control it, have it reviewed by others, but best of all, apply it to a production DB in a controlled (and repeatable) fashion.
Summary
I really haven't gone in to much detail about how this is all actually implemented. Really what I want people to take out of this post is that it's possible to have a process which allows people (who are not necessarily developers by trade) to get their changes in to a production database, but in a controlled manner.
Comments, as well as pull requests to the associated github project, are welcome!